|
Document number
|
ISO/IEC/JTC1/SC22/WG21/D1483R1 |
|
Date
|
|
|
Reply-to
|
Ben Boeckel, Brad King, Robert Maynard, Bill Hoffman, ben.boeckel@kitware.com, brad.king@kitware.com, robert.maynard@kitware.com, bill.hoffman@kitware.com |
|
Audience
|
EWG (Evolution), SG15 (Tooling) |
1. Abstract
A C++ "module" system has been proposed to communicate declarations among translation units. This requires build systems to account for dependencies implied by module definition and usage. The Fortran language has a module system that requires similar support from build systems. We describe how CMake implements support for Fortran without manual module dependency information.
2. Changes
2.1. R1 (Feedback)
Include description of build execution strategies for available to C++.
2.2. R0 (Initial)
Description of Fortran’s module system and CMake’s solution to building it given the capabilities of existing toolchains.
3. Introduction
This paper describes how Fortran modules affect build systems and the approach CMake uses to support them with the ninja build tool[ninja]. It is a refinement of an approach used by CMake’s Makefile generator since 2007 that works with stock make tools. CMake’s approach has been deployed with success since 2016 in its Ninja generator along with a ninja tool patched to support dynamically-discovered dependencies[ninja-patch].
4. Fortran module primer
A Fortran source file may define a module:
module math contains function add(a,b) real :: add real, intent(in) :: a real, intent(in) :: b add = a + b end function end module
Compiling this source produces both an object file and a math.mod file generated by the compiler to describe the module’s interface. Another Fortran source file may use the module:
program main use math print *,'sum is',add(1., 2.) end program
When the compiler sees use math it looks for a math.mod file and reads it to load its interface. This makes the add function available. Fortran has no designated location for module use statements and they may be made in any scope.
These two sources may not be compiled concurrently because the module definition and usage imply a dependency. Furthermore, if the first source is updated in a way that modifies math.mod, then the second source must be re-compiled. A build system must discover this dependency in order to build and re-build the program correctly.
Fortran module syntax is interpreted by the compiler after preprocessing. This affects the build system in two ways:
-
The build system must preprocess source files to extract module dependencies because Fortran module constructs may appear behind preprocessor conditions and macro expansions.
-
The build system may preprocess source files concurrently because preprocessing is independent of Fortran module constructs.
In all known Fortran compiler implementations, the file name of module outputs is determined by the compiler, but the location of this file may be specified by the build tool.
5. How CMake handles Fortran modules
5.1. Input to the build system
CMake projects organize source files into groups called "targets". Each "target" corresponds to a final build artifact such as a library or executable. CMake code specifies for each target the list of source files to be compiled for that target and a list of other targets (libraries) from which the sources may use symbols.
For example, a CMake project may specify three library targets each composed of three Fortran source files:
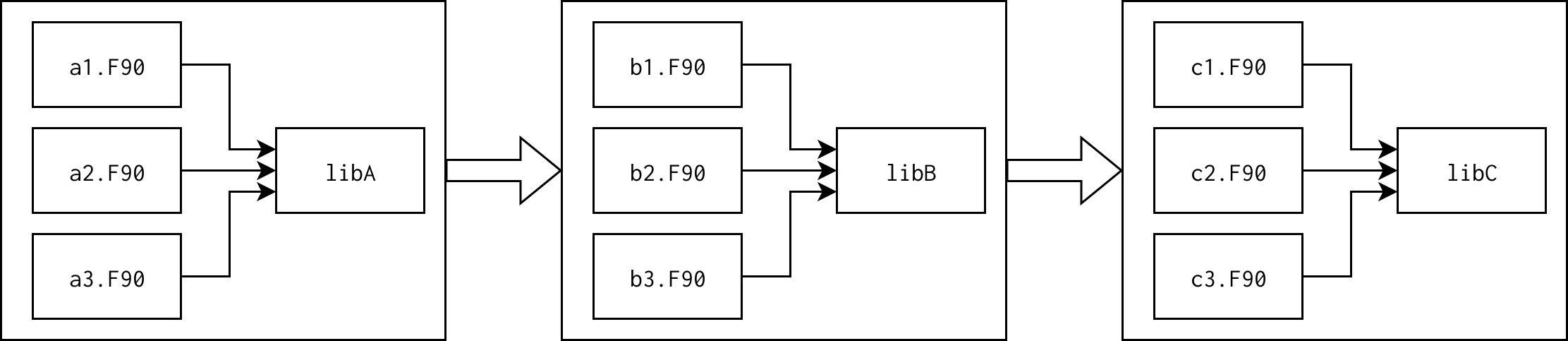
In this diagram arrows point from dependency to dependent (inputs to outputs). There are three targets:
-
Library A containing sources a1.F90, a2.F90, and a3.F90. These sources may use interfaces from each other.
-
Library B containing sources b1.F90, b2.F90, and b3.F90. These sources may use interfaces from each other and from A.
-
Library C containing sources c1.F90, c2.F90, and c3.F90. These sources may use interfaces from each other and from B.
From this high-level specification CMake must determine how to compile the source files and build the libraries correctly and efficiently. A correct build means that when a source file changes, all outputs which are affected by the source’s contents are recreated. An efficient build means that any outputs which are not affected by the source’s contents are not recreated.
As CMake supports generation of sources during the build, dependencies among sources implied by their content, such as those created by use of Fortran modules, must be discovered dynamically as the build proceeds. For a given source file, generated or not, CMake proceeds with dependency analysis once it is available and up-to-date.
5.2. Notation used in build graphs
In the following build graphs, edges are labeled with the rule that is performed in order to process the input into the output. Intermediate nodes in the build graphs are labeled with representative filenames and may not match what CMake uses. The rules used are as follows:
-
The preprocess rule is performed by compilers and handles resolution of #include and #define directives. During execution of this rule is also when CMake expects header dependency information to be made available (e.g., gcc -M or cl /showIncludes). The .pp.f90 extension is used for these outputs.
-
The scan rule is performed by CMake to extract the required and provided modules of a source file. The .ddi extension is used for these outputs.
-
The collate rule is performed by CMake to collect information from scan rules of source files as well as the collate rule of dependent targets and writes the module dependency information into a target-wide dynamic dependency file. The .dd extension is used for these outputs.
-
The compile rule is performed by the compiler using the preprocessed source file to create object code for use by the linking step. This rule cannot be run until the build tool takes the output of the collate rule into account in order for the compilation subgraph to be correct. The compiler does not need to read the output of the collate rule. The .o extension is used for these outputs.
-
The link rule is performed by compilers and takes the results from compile rules to create a library or executable.
Edges from collate rules into compile rules are indicated by a blue dashed line to indicate that they are order only dependencies. An order only dependency is one that must be run before, but does not force the depending rule to rerun. Dynamically discovered outputs and dependency links are specified in green and use a curved edge.
5.3. Build graph for a single source

This graph shows the compilation subgraph for a single source, a1.F90 compiled as part of the A library. At the left, we have the input source file and at the right is the resulting object file. In between, CMake adds rules to extract the module dependency information required to get the build correct. The object compilation uses the preprocessed source as input so that the compiler, as an optimization, does not need to rerun the preprocessor.
5.4. Build graph for a single target
For a target containing multiple sources, the single source graphs are combined into a target-wide graph where all source file graphs are joined on the shared .dd node for the target.
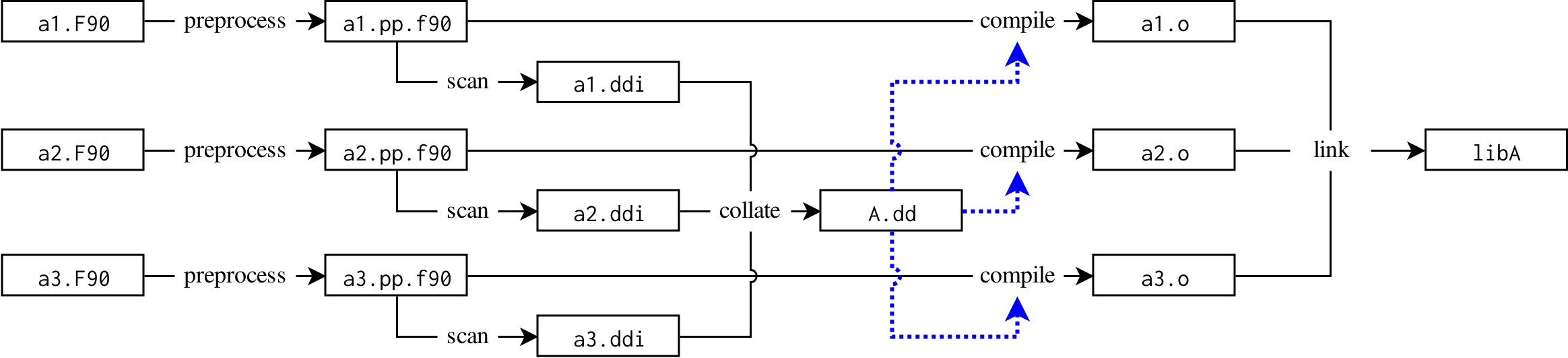
Note that in this graph, there are no interdependencies between compilation outputs. These will be discovered during the build.
Kitware’s patched ninja branch has support for recognizing the dynamic dependency specification edge as such and modifies the graph to be correct at build time. This involves recognizing the special dynamic dependency edges and, prior to running rules with such an incoming edge, waits for the specified file to appear and then updates the build graph with the additional information specified in the file. Given a module math provided in a1.F90 and consumed in a2.F90, the build graph ends up with the following rules:
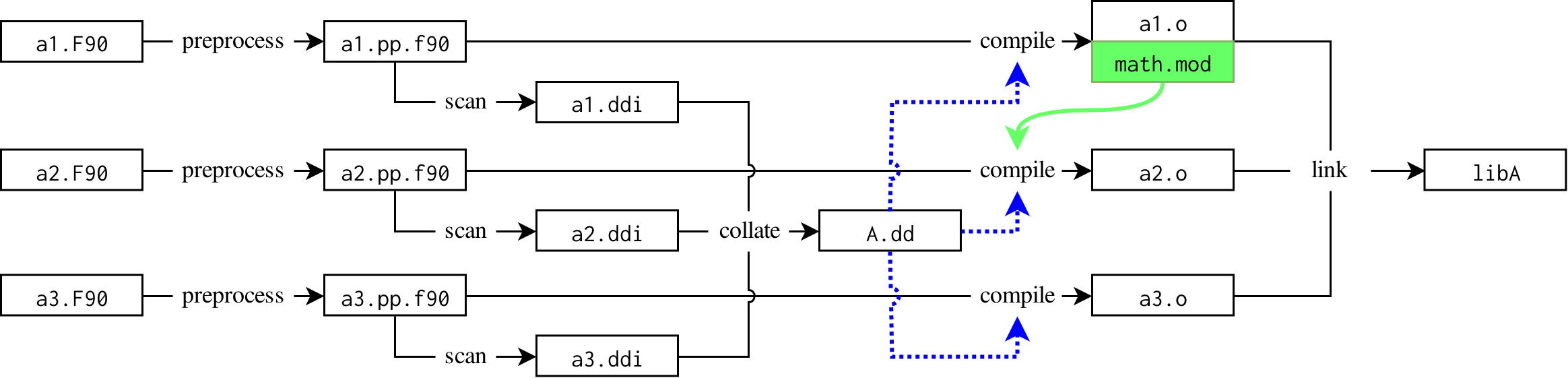
Once the A.dd output has been brought up-to-date and read, ninja updates its build graph. With this information, it is known that, in parallel, a3.F90 and a1.F90 may be compiled since there are no dependencies between them and that a2.F90 must wait for the compilation of a1.F90 for the math.mod to made available which required to compile a2.F90. It is also known that if a1.F90 changes, a2.F90 may need recompiled, but a3.F90 will never need to be. As the dependency is also on the math.mod file directly, if a1.F90 is modified and recompiled, if math.mod is not changed, then a2.F90 is still considered up-to-date and not recompiled unnecessarily. Further, it is known that if a3.F90 is changed to gain a dependency on math.mod, the requirement on the A.dd generation means that the new dependency will be discovered and that the a1.F90 must be checked for changes as well.
5.5. Build graph for multiple targets
When multiple targets are built, their dependency graphs are linked together in the following way:
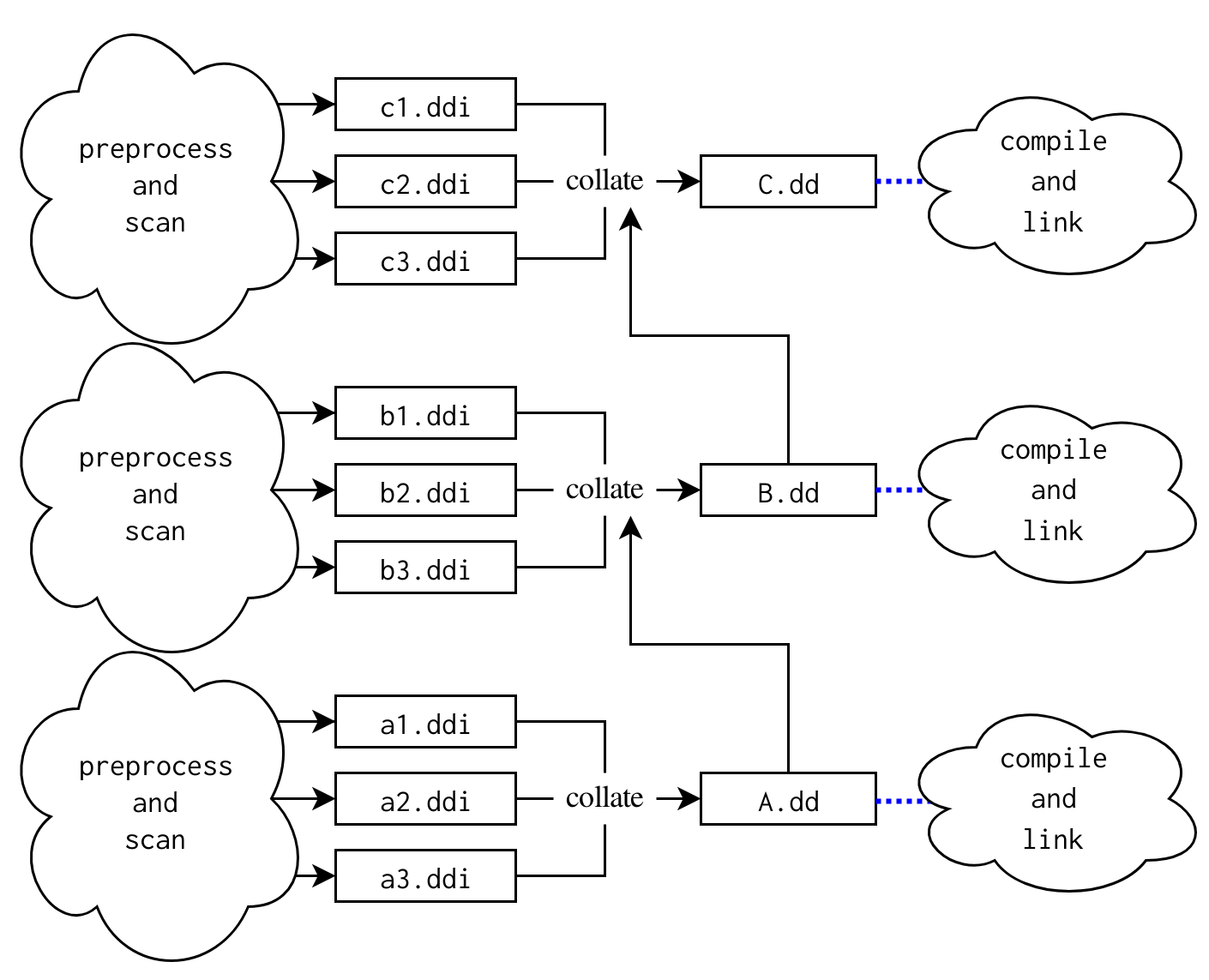
The .dd files for direct dependent targets are additional inputs to the target’s .dd file. This allows modules contained within a source file in library B to be used in a source file in library C while still getting dependencies correct.
5.6. Special code CMake provides to implement Fortran module support
-
A Fortran parser based off of makedepf90 [makedepf90] version 2.8.8 and heavily modified since its inclusion in CMake in 2007. This is needed to detect module definitions and usage in translation units since compilers do not currently provide a way to extract this information without compiling.
-
A patched ninja with support for dynamically-discovered dependencies.
-
The dynamic dependency collator[cmake-collator].
The support added to ninja in order to support this compilation model includes the addition of dyndep rules and attributes. When dyndep = <file> is specified on a build statement, ninja loads the file and parses it in order to extract the additional information needed to order the object compilation build rules properly. The format is restricted to specifying additional outputs of another rule and additional compilation dependencies of the current rule. This support has been submitted upstream and is in the process of being reviewed[ninja-patch-pr].
6. Applicability to C++ modules
The above approach is applicable to C++ module dependencies under the requirement that the set of modules imported and exported by a translation unit be detectable without considering content of other translation units. In particular, this means that importing a normal module (e.g. import X;) may not affect preprocessing in a way that changes the set of header units included or modules subsequently imported or exported by the translation unit. Note that importing a legacy header module (e.g. import "y.h") is allowed so long as the preprocessor can discover the available macros.
This approach assumes that there is an on-disk representation of the module that gets updated when the module changes. This representation need not contain the contents of the module itself, only that it represent the module. Any module without an on-disk representation should not be mentioned in .ddi files. This is similar to header units which do not exist on disk and should not be mentioned in dependency information.
6.1. Build graph overview
Module dependency scanning must be integrated into the build graph. It cannot be done ahead of time by a build system generator because generated source files may not be available and up-to-date.
With compiler help as proposed below, C++'s build graph will be able to skip the separate preprocess rule within the build and instead use a single scan rule. This results in a build graph with fewer required rules. The following graph shows the overall structure of a C++ build. The numbers on the nodes show the earliest possible scheduling of the rule generating the marked output.
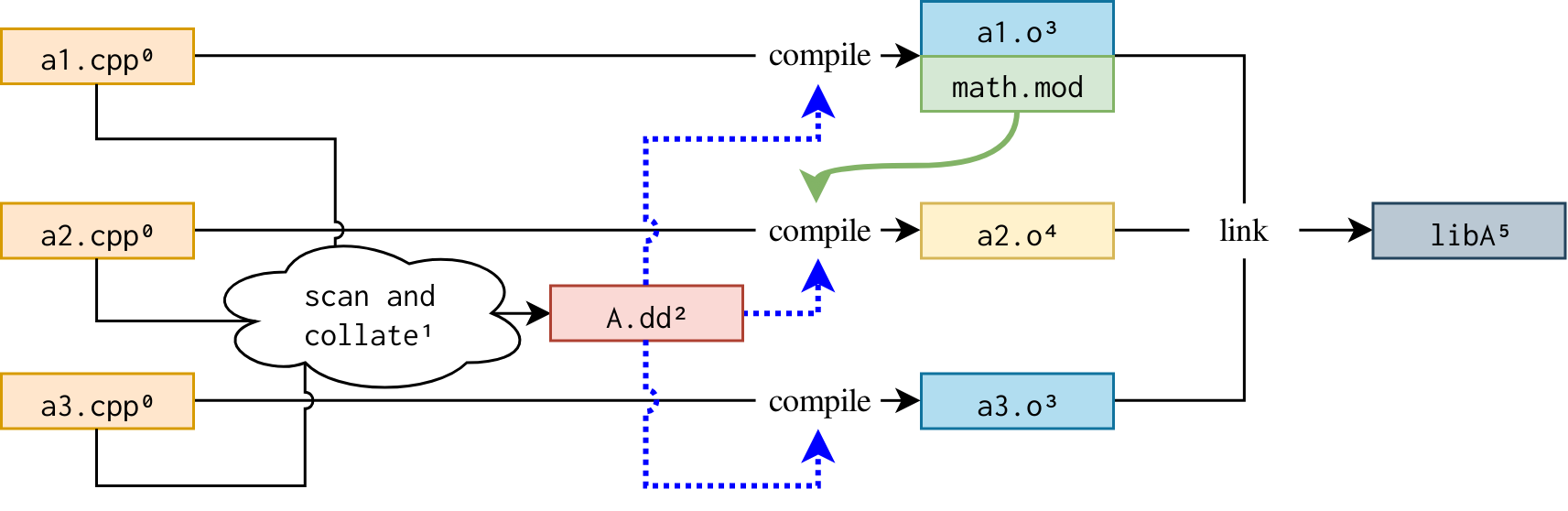
The green, curved edge for math.mod is found at build time through the A.dd file.
There is one scan and collate rule for each target. This strategy makes scanning more granular and efficient and also supports cases involving source files generated by executables participating in the same build graph:
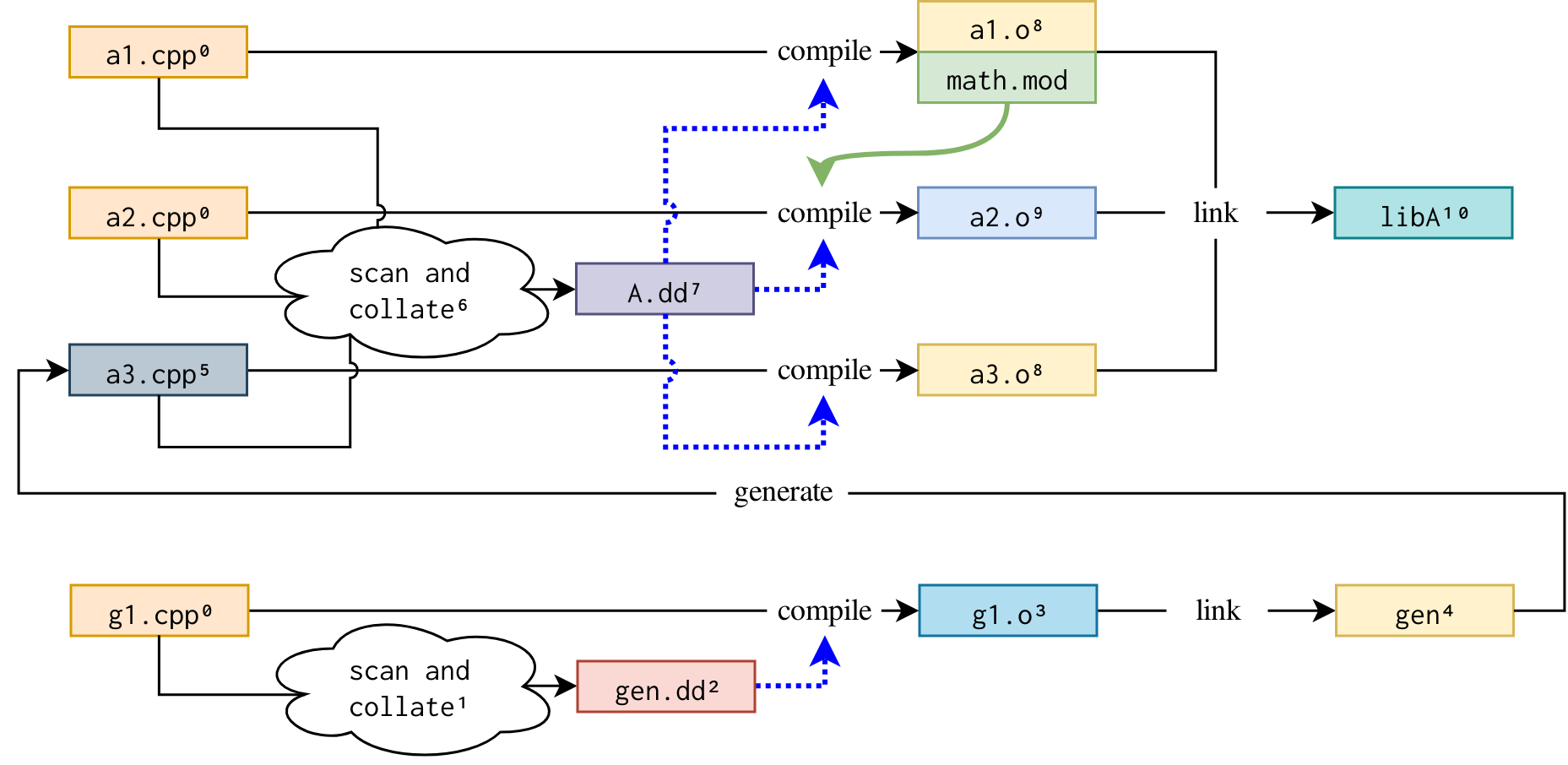
Here, a3.cpp is generated by a tool gen created during the build. Performing its scan rule must wait for it to be created, but gen has its own sources that also need a scan and collate rule. Note also that a1.o and a3.o are still able to be scheduled together since their compile rules do not have interdependencies.
6.2. Strategies for scan and collate rules
For the scan and collate cloud, there are a number of possible implementations.
6.2.1. Scan sources independently then collate
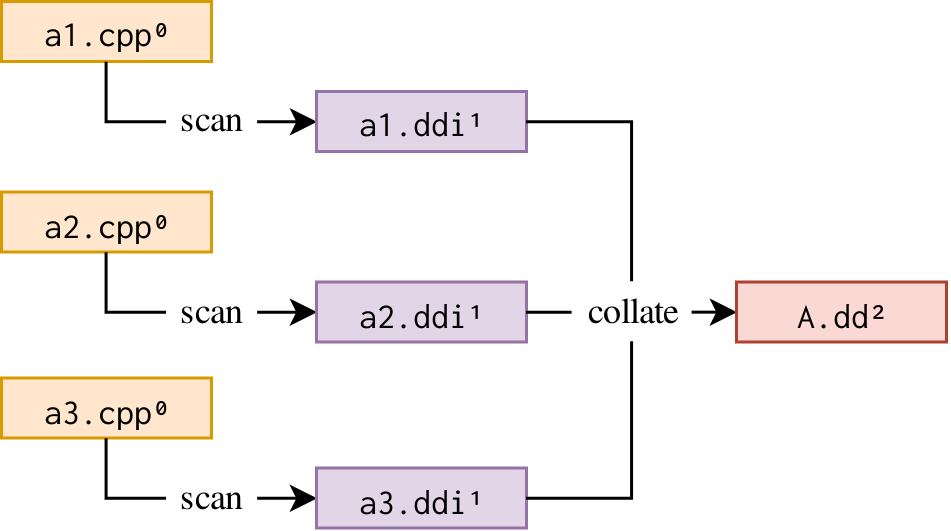
Here, each source file is scanned individually. This might be preferred for:
-
incremental builds where the number of changed files between builds is small because scan rules read files only when necessary;
-
projects with "wide" build graphs where the number of scan steps at a given build graph depth can saturate a build machine setup; and
-
projects with lots of generated sources because where scanning of non-generated sources does not need to wait for their generation.
6.2.2. Scan sources all-at-once then collate
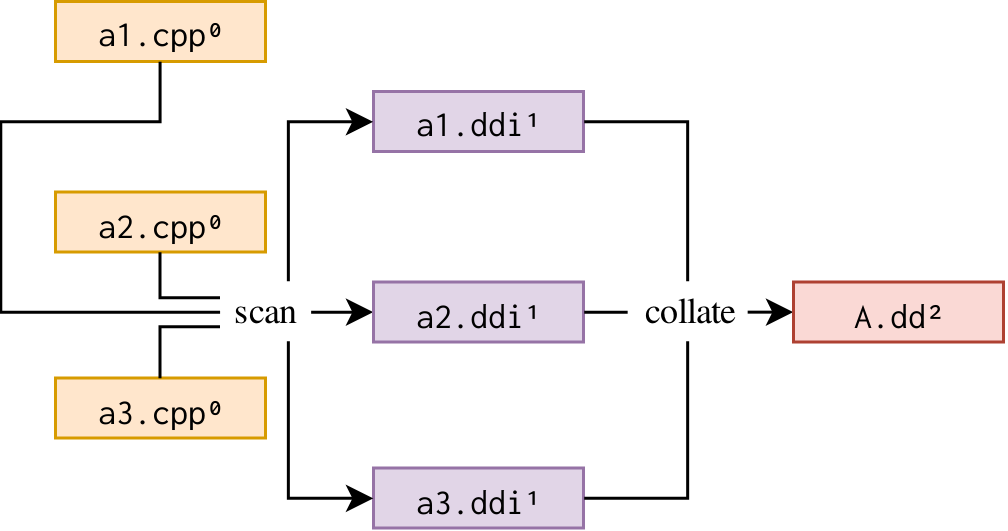
With this structure, all source files within a target are scanned at once. This might be preferred for:
-
from-scratch builds;
-
platforms with expensive process execution;
Note that this requires a more complex scan tool since it must internally decide whether to update an output file based on the state of the corresponding input source file in order to avoid running other rules unnecessarily.
6.2.3. Scan sources and collate all-at-once
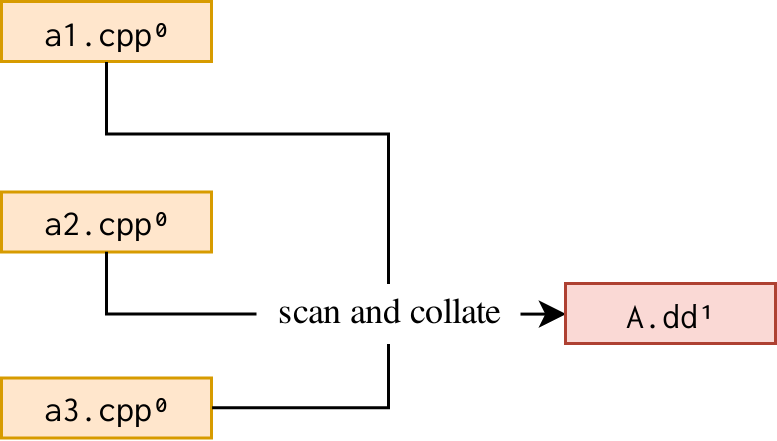
In this graph, sources within a target are scanned together and the collate output is output in a single step. This is a more extreme version of the previous example and requires even more complexity within the given tool. It must do some internal bookkeeping to determine whether to read input files based on whether they’ve been modified and only update the output if necessary in order to avoid running other rules unnecessarily.
6.3. Module partitions
C++ modules, as proposed, contains the concept of module partitions. Our analysis is that these are analogous to Fortran’s concept of submodules[fortran-submodules] from the perspective of the build tool and the solution described here handles them gracefully.
While the wording proposed in [P1302R1] can make the job of build tools easier, it is not required in order for dependency graphs to be correct.
6.4. Legacy header modules
Legacy header modules are the leading worry about the current language proposed in [P1103R2].
6.4.1. Macros are tractable as-is
The problem of legacy header modules has been described in [P1052R0]. We believe that the Merged Modules as described in [P1103R2] does not fall afoul of the issues raised.
Making modules capable of exporting macros will make import a preprocessor directive rather than (or, more precisely, in addition to) a language declaration since via exported macros it will now be able to affect the preprocessor state. This "hoisting" of import into the preprocessor will significantly complicate module dependency extraction.
Specifically, the approach described in the previous section will no longer work since a previously-imported module may now effect (via a preprocessor macro) the importation of subsequent modules. For example:
import foo; // May export macro FOO. #ifdef FOO import bar; #endif
This worry about a module import that is not a legacy header module is not reflected in the language of [P1103R2]. The only mention of macros in the Merged Modules paper is:
A sequence of preprocessing-tokens matching the form of a pp-import instructs the preprocessor to import macros from the header unit (100.3) denoted by the header-name. The ; preprocessing-token shall not be produced by macro replacement (14.3). The point of macro import for a pp-import is immediately after the ; terminating the pp-import.
A macro directive for a macro name is a #define or #undef directive naming that macro name. An exported macro directive is a macro directive occuring [sic] in a header unit whose macro name is not lexically identical to a keyword. A macro directive is visible at a source location if it precedes that source location in the same translation unit, or if it is an exported macro directive whose header unit, or a header unit that transitively imports it, is imported into the current translation unit by a pp-import whose point of macro import precedes that source location.
While not explicit, we are assuming that header units may be looked up using the same rules as #include directives and therefore the preprocessor can find the contents of the imported header unit. We are expecting that if the header cannot be found, that the preprocessor will exit with failure because it cannot continue. Legacy header units should be included in the list of files read by the preprocessor so that when they change, the build tool may rerun the preprocess/scan step.
6.5. Concern about synthesized header units
We have a concern about the specific language used in the Merged Modules proposal [P1103R2].
A module-import-declaration that specifies a header-name H imports a synthesized header unit, which is a translation unit formed by applying phases 1 to 7 of translation (5.2) to the source file or header nominated by H, which shall not contain a module-declaration. [ Note: All declarations within a header unit are implicitly exported (100.2), and are attached to the global module (100.1). —end note ] An importable header is a member of an implementation-defined set of headers. H shall identify an importable header. Two module-import-declarations import the same header unit if and only if their header-names identify the same header or source file (14.2). (emphasis added) [ Note: A module-import-declaration nominating a header-name is also recognized by the preprocessor, and results in macros defined at the end of phase 4 of translation of the header unit being made visible as described in 14.4. —end note] A declaration of a name with internal linkage is permitted within a header unit despite all declarations being implicitly exported (100.2). If such a name is odr-used outside the header unit, or by a template instantiation whose point of instantiation is outside the header unit, the program is ill-formed.
This implies that these two module import declarations are equivalent:
#define PROVIDE_SOME_API import "legacy_header.h";
import "legacy_header.h";
Where the PROVIDE_SOME_API definition affects the contents of "legacy_header.h". We propose that the language be updated in one of the following ways:
-
Mention that the preprocessor context of the synthesized header unit should be taken into account when determining whether two module-import-declarations import the same header.
-
That compilers be able to apply different preprocessor contexts to a header unit from used different locations.
6.6. Synthesized header unit outputs may pose a problem
Synthesized header units, as worded, pose a problem that cannot be solved by build tools alone without compiler assistance[P1103R2].
When a #include appears within non-modular code, if the named header file is known to correspond to a legacy header unit, the implementation treats the #include as an import of the corresponding legacy header unit. The mechanism for discovering this correspondence is left implementation-defined; there are multiple viable strategies here (such as explicitly building legacy header modules and providing them as input to downstream compilations, or introducing accompanying files describing the legacy header structure) and we wish to encourage exploration of this space. An implementation is also permitted to not provide any mapping mechanism, and process each legacy header unit independently.
A module generated implicitly by a synthesized header unit import has no single, unique translation unit that generates it. Therefore the build tool cannot associate any on-disk module representation with a unique compile rule that produces it. It is up to compilers to properly cache synthesized header units taking command line flags into account.
Further research may offer alternatives. One possibility is that if the compiler were to implement the scan rule, as proposed below, it could mark required legacy header module outputs specifically in the .ddi file. Then the collate rule could assign them to unique compile rules. Without compiler support, the custom scan rule tool must manually determine which compile flags affect legacy header modules.
7. How can we help each other?
This is a complex problem, but as we have shown here, solutions do exist. However, this does not mean everyone has to go it alone.
7.1. How can compilers help build tools?
Currently CMake’s Fortran support includes its own Fortran parser needed to implement the scan rule in its build graphs. This can be provided as early as Phase 4 of the C++ compilation model. The parser is a sizeable amount of code to extract a small amount of important information that could be provided by the compiler instead. Ideally a compiler should provide a way to extract the following information in a single invocation on a source file without reading or writing any modules and without compiling:
-
The names of modules imported by the translation unit.
-
The names of modules exported by the translation unit (at most one for C++).
-
The names of synthesized header units imported by the translation unit.
-
The paths of files read by the preprocessor (e.g. gcc -M).
Such a feature would help C++ build systems immensely. It would prevent the need to implement a C++ parser for the sole purpose of extracting this information and it would make it possible to skip the explicit intermediate preprocess rule in the build graph.
In order for the dependency resolution to work, a compiler must have a way to specify the location of module files and either accept a filename for modules or include the compiler’s filename in its scan output.
A standing document describing the specific information necessary and useful for build tools might be useful for C++ to provide, but we leave that decision to the discretion of WG15.
Note that the scan rule may choose to also write out the preprocessed source. This can allow for the same optimizations as Fortran and avoid duplicating the preprocessor’s work and compile the preprocessed source directly. This may not be possible for a number of reasons:
-
Compilers may have different behavior between a source and its preprocessed output[preprocess-differences].
-
Compilers may provide better diagnostic messages based on the macros used in the original source file.
-
There may be multiple preprocessor outputs for a single compilation (for multiple platform compilations, e.g., macOS universal binaries).
Ideally, compilers will provide ways to map module names to module representation files to support isolated builds. An approach similar to providing the compiler a list of modules without duplicate entires would be sufficient. This avoids dangers such as module files shadowing each other in a search path approaches such as module search directories. Additionally, the compiler may avoid the cost of opening a file per module if the format supports combining multiple modules and the associated binary representations.
7.2. How can build tools help each other?
Build tools will all have to implement a solution like this in order to compile C++ modules correctly. A single tool for performing the collate rule may be shared among build tools to reduce inconsistencies between build tools.
If compilers do not provide a tool for the scan rule, such a tool may also be shared among build tools.
8. References
-
[cmake-collator] Brad King. CMake’s collator implementation as of 06 Feb 2019. https://gitlab.kitware.com/cmake/cmake/blob/062cfd991faac000d484c74e5af7d65726c655dc/Source/cmGlobalNinjaGenerator.cxx#L1795-1950.
-
[makedepf90] Erik Edelmann and contributors. Note that upstream seems to have disappeared; this repository is based on release tarballs. https://github.com/outpaddling/makedepf90.
-
[ninja] Eric Martin and contributors. Ninja build tool. https://github.com/ninja-build/ninja.
-
[ninja-patch] Brad King. Kitware’s branch of ninja to support Fortran modules https://github.com/Kitware/ninja/tree/kitware-staged-features#readme.
-
[ninja-patch-pr] Brad King. Upstream pull request for Fortran support in ninja https://github.com/ninja-build/ninja/pull/1521.
-
[preprocess-differences] Boris Kolpackov, Stephan T. Lavavej, et al. https://www.reddit.com/r/cpp/comments/6abi99/rfc_issues_with_separate_preprocess_and_compile/.
-
[P1052R0] Boris Kolpackov. Modules, Macros, and Build Systems. http://open-std.org/JTC1/SC22/WG21/docs/papers/2018/p1052r0.html.
-
[P1103R2] Richard Smith. Merging Modules. http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p1103r2.pdf.
-
[P1302R1] Isabella Muerte and Richard Smith. Implicit Module Partition Lookup. http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2019/p1302r1.html.
-
[fortran-submodules] Jason Blevins. Fortran Submodules. http://fortranwiki.org/fortran/show/Submodules.